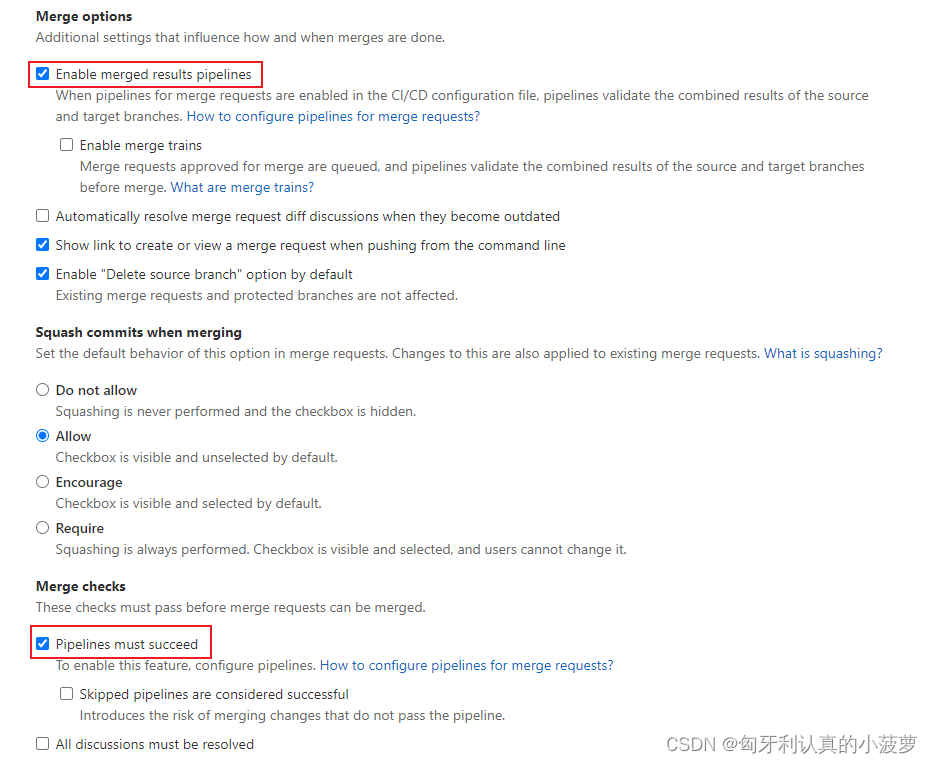
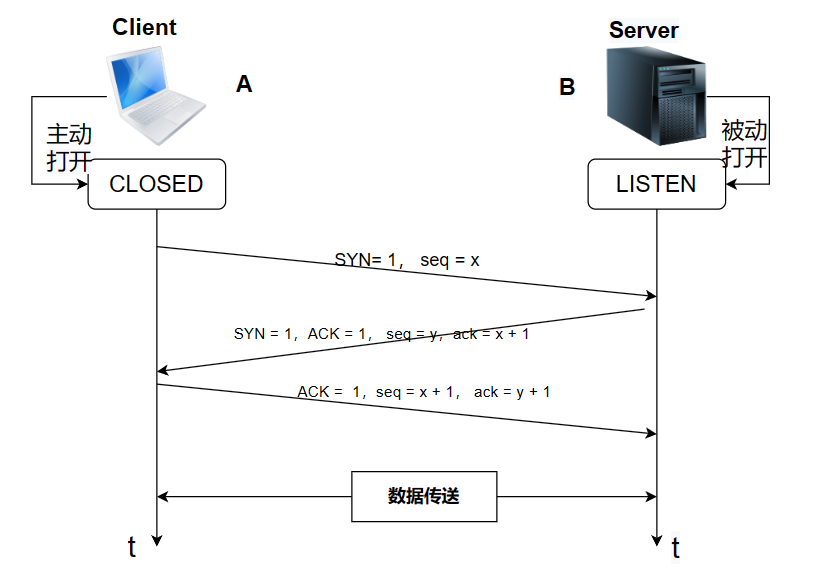
目录
前言
粉丝及官方意见说明
第十九章一些学习笔记
第十九章一些操作方法
树模型、随机森林与最近邻元素法
树模型
数据准备
具体操作
结果解释
对案例的进一步分析
结果解释
考虑应用模型时的成本与收益
保存新数据
在选项中看错误分类成本和利润
结果解释【表格读法与前面相同】
考虑进一步细分和减枝(交叉验证与修减算法不能同时使用)
结果解释
将模型输出为判别程序
随机森林模型
假设数据
具体操作
对话框介绍
结果解释
结束语
前言
#一起加油
#本期内容:树模型、随机森林与最近邻元素法
#由于导师最近布置了学习SPSS这款软件的任务,因此想来平台和大家一起交流下学习经验,这期推送内容接上一次高级教程第十八章的学习笔记,希望能得到一些指正和帮助~
#截止今天到今晚SPSS教材也终于是学完了.....后面每天一更了
粉丝及官方意见说明
#针对官方爸爸的意见说的推送缺乏操作过程的数据案例文件澄清如下:1、操作演示的数据全部由我本人随意假设输进去的,重在演示操作;2、本人也只是在学习阶段,希望友友们能谅解哈,手里有数据的宝子当然更好啦,没有咱就自己假设数据练习一下也没多大关系的哈;3、我也会在后续教程中尽量增加一些数据的必要性说明;4、大家有什么好的意见也可以在评论区一起交流吖~
第十九章一些学习笔记
- SPSS树模型相对于经典统计模型的优点:1、模型容量大;2、适用范围广。与其他数据挖掘方法【神经网络或支持向量机等模型】相比,其优点有:1、分析原理与所得结果简单易懂;2、在相同数据量、相同软件和硬件环境下,构建树模型的时间远比其他数据挖掘算法短;3、适用面广,目标变量既可以是离散变量,又可以是连续变量。树模型的缺点:1、不能对影响因素的作用大小进行精确的定量描述;2、对于线性关联、无交互作用的数据,树模型会给出非常复杂的结果,使简单问题复杂化,其分析效果和模型解释性均不如普通统计模型;3、需要较大样本量才能保证逐层细分后单元格内任有充分的样本数;4、对结果的解释和应用过于灵活,没有严格的标准可以遵循。--统计分析高级教程(第三版)P365
- SPSS中常见的树模型算法:1、CHAID算法【chi-squared automatic interaction detector,卡方自动交互检测,将卡方检验作为数分类的基本方法,利用P值大小依次纳入最有影响的变量,生成结果为多叉树,该算法最大的缺陷在于从原理上只能针对分类自变量和分类因变量进行分,析对于连续自变量,则必须将其转换为分类变量方可纳入分析】;2、穷举CHAID算法【核心思想是搜索每个预测变量所有可能的拆分,然后从中择优,但任然只能用于分类自变量】;3、CRT算法【即分类数与回归数的缩写,也记为CART算法,目前应用最广泛,若因变量为分类变量,即为分类树模型,若因变量为连续变量则称为回归数模型】;4、QUEST算法【quick,unbiased,efficient statistical tree,一种新的二叉树算法】;5、C5.0算法【计算速度比较快,占用的内存也比较少,以信息熵(信息量的数学期望)的下降速度作为确定最佳分值变量和分割阈值的依据】。--统计分析高级教程(第三版)P375-378
- SPSS随机森林的主要思想:通过生成成百上千棵树,以充分发掘有效信息,然后再将这些树模型所携带的信息汇总起来构建一个信息量尽可能充分的模型。--统计分析高级教程(第三版)P378
- SPSS中随机森林的预测误差主要来源两个方面:1、森林中树间的相关性,相关性增大时,预测误差也会上升;2、森林中每棵树的强度,即预测能力,预测误差小的树是一个很好的分类器,单棵树的强度上升会使森林的预测误差下降。--统计分析高级教程(第三版)P379
- SPSS中K-最近邻元素法的特点:1、分类的结果与K的大小有关,K的取值越大,计算开销也越大;2、K-最近邻元素模型不能给出明确的分类规则,这就意味着,K-最近邻元素法所得到的结果很难在专业上得到解释;3、适用范围广,对变量的分布无要求;4、K-最近邻分类假设训练样本的多维空间中,各个类别的数据点分布基本上是均匀的,但这一假设在很多情况下并不能得到满足。--统计分析高级教程(第三版)P386-387
第十九章一些操作方法
树模型、随机森林与最近邻元素法
树模型
结(node):一个样本群体在树模型中表示为图中的一个节点,被称为结。
根(root):树的起始点(包括所有的案例)。
叶(leaf):树的终止点。
分枝(split):即依据怎样的原则将样本分为不同的子样本。
数据准备
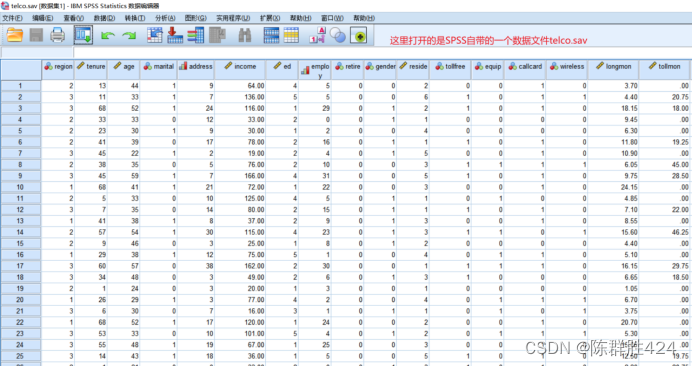
具体操作
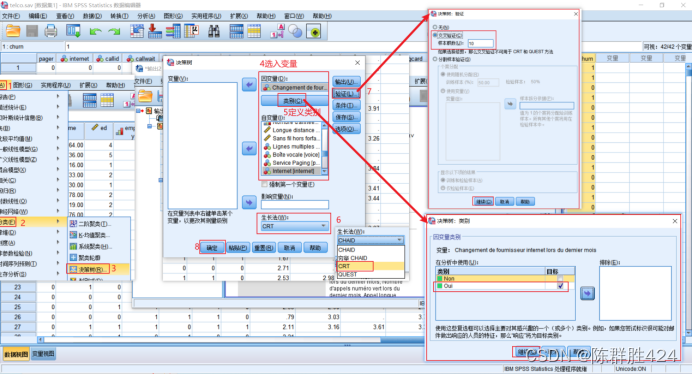
结果解释
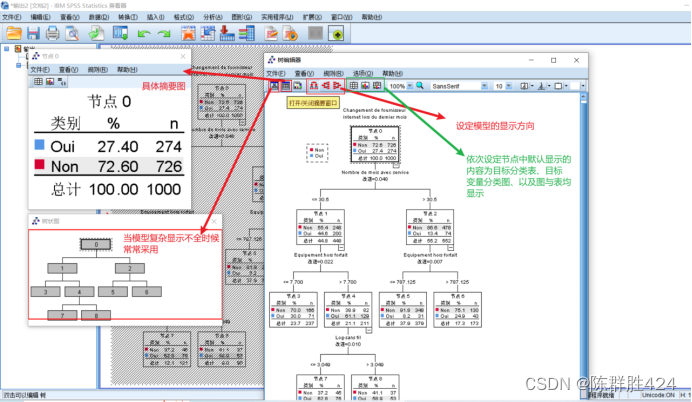

对案例的进一步分析
结果解释
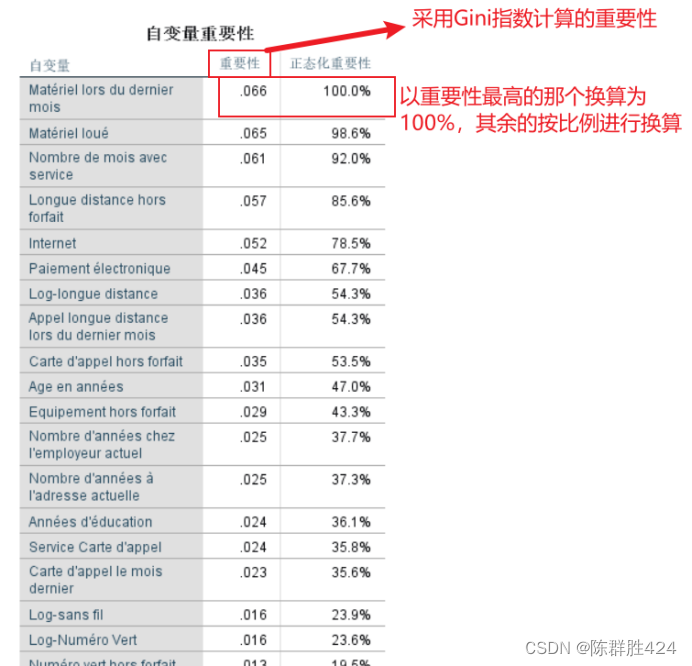
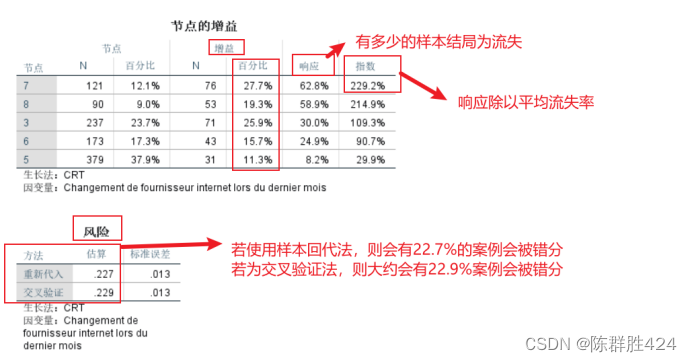
考虑应用模型时的成本与收益
模型用于预测时会有误差,因此在将模型结果用于实际工作时就需要考虑一个误分类成本。
保存新数据
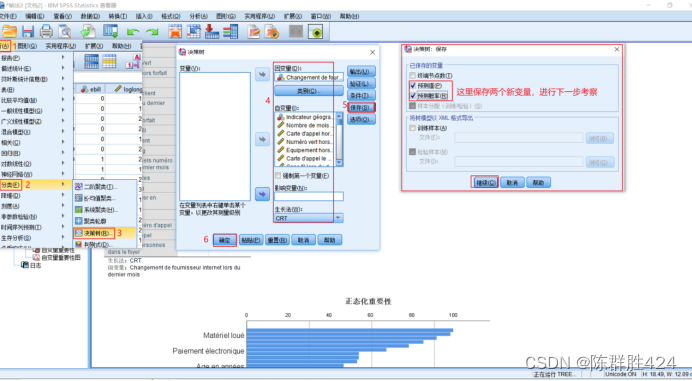
在选项中看错误分类成本和利润
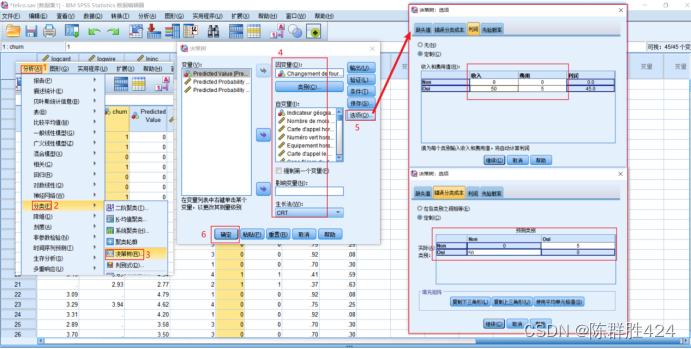
结果解释【表格读法与前面相同】
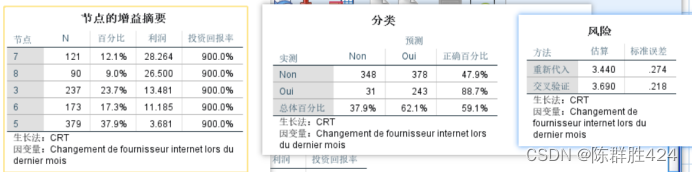
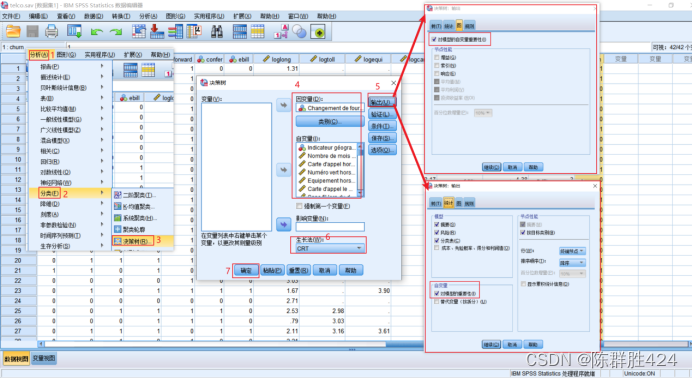
考虑进一步细分和减枝(交叉验证与修减算法不能同时使用)
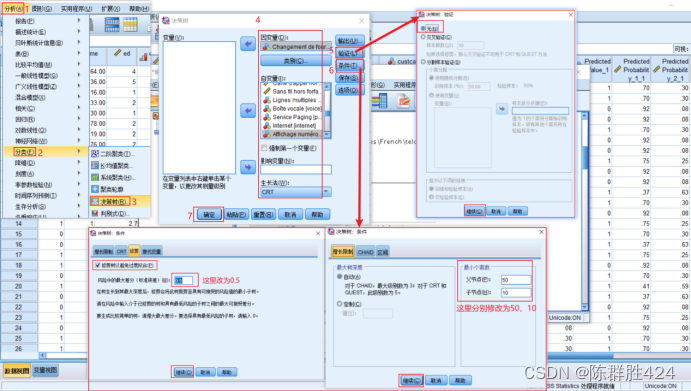
结果解释
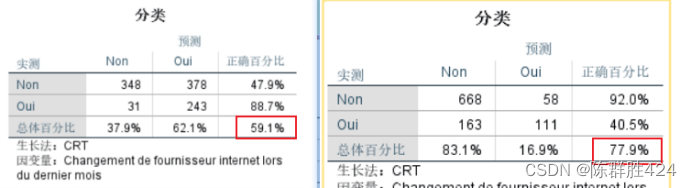
可见模型的正确率有所改善
将模型输出为判别程序
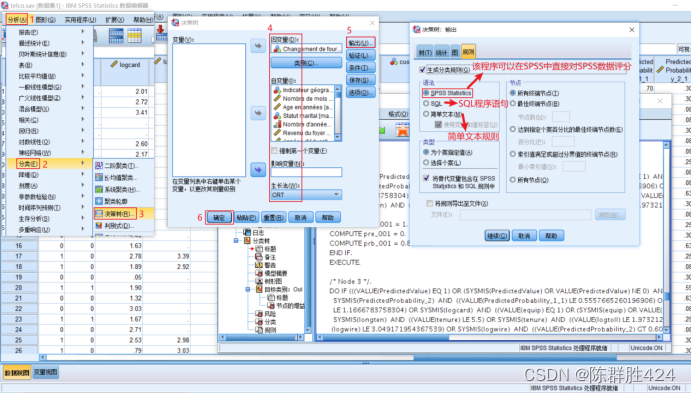
随机森林模型
SPSS本身并没有提供该模型,需要调用R插件,故这里无法演示,后续考虑编程的算法来实现。
最近邻元素法【nearest neighbor,又称为memory-based reasoning,MBR】
这是一种根据新案例与其他案例的相似程度来进行分类的方法。
花种的类别判别
假设数据
具体操作
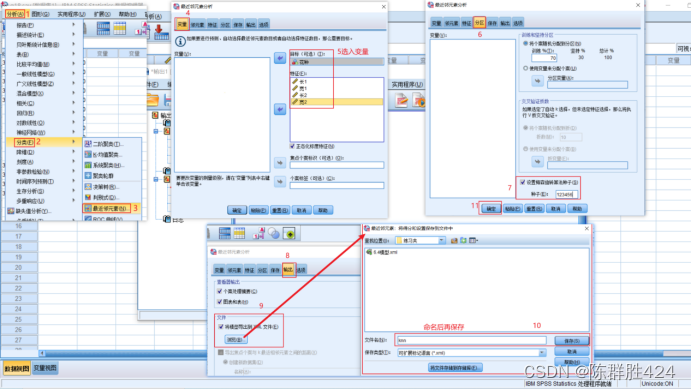
对话框介绍
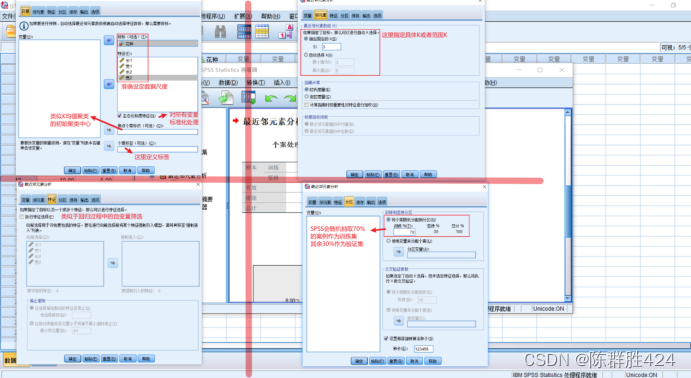
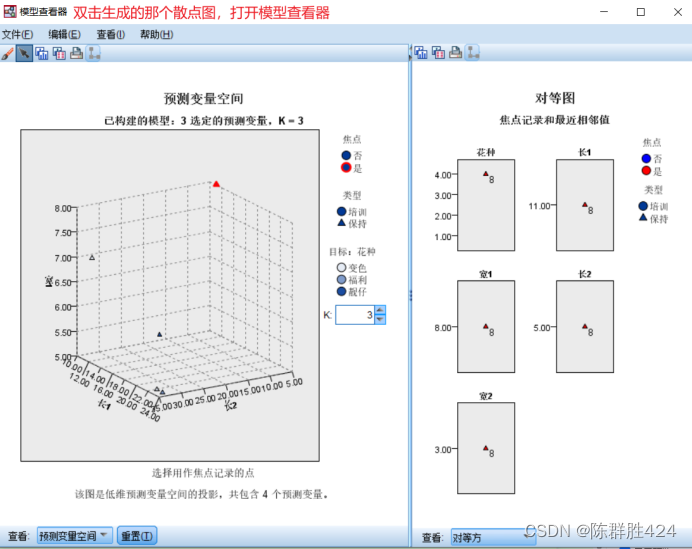
结果解释
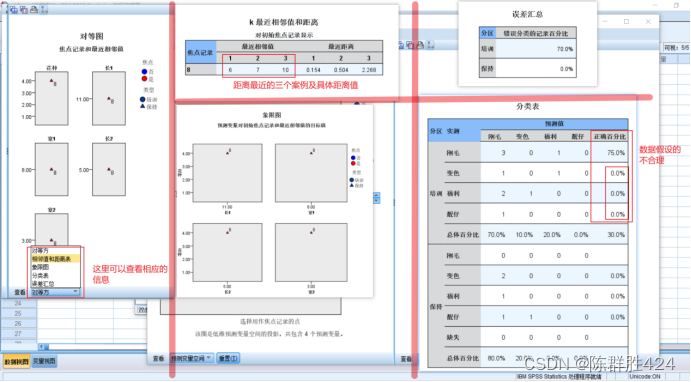
结束语
#好啦~,以上就是我SPSS第三十七期学习笔记——高级教程第十九章的学习情况啦~,希望能与大家交流学习经验,共同进步吖~
#也非常感谢大家对我的一路陪伴,宝子们的关注、支持和打赏就是up儿不断更新滴动力,我近期也会坚持学习SPSS,更新相应的学习内容及笔记到平台上,咱们下期高级教程不见不散~